Our path to get to know you.
Who are you? To have the answer to this, we could ask a set of questions and do our best guess. But it’s not that easy, is it? Who we are, who we show we are and who other people see we are can all be different personas.

At Mindmymind, we took the challenge of navigating through every personal nuance to get to know you for who you are. In these troubled waters, we have a lot of uncharted territory, but we do have a good compass that points us in the right direction. In this article we plan to go through our plans and current state in this endeavor. The journey of this post will follow our values of Know, Show, Go, Flow.
If you can't measure it, you can't improve it.
As data-driven individuals, we do not want to evaluate the quality of our work in suppositions and feelings. At each step, we need to know if it is a step forward or a step back. For that, we gathered a team of typology experts to evaluate a group of people in regards to their personality type. We sent these individuals questions in different sets that we thought would give us insights into their personality type.
We also asked them to fill out two open typology questionnaires online. The first is 16Personalities which is one of, if not the, main reference for an MBTI personality open test. The other is Crystal Knows which has a snappier version of the test more in line with what we would want to present in our app.
Building the compass.
Building the infrastructure for all this data labeling took a while, and actually obtaining the types for a meaningful set of people took even longer. With 16 types, having 50 people labeled gives us an average of around 3 people per type. And since types are not evenly distributed, it’s possible that not all types are represented in that sample!
Additionally, not all collected user sessions from our test group allowed us to attribute confident types. Out of 498 user sessions analyzed by our experts, we were able to confidently type only 131. With all that, our current data type distribution looks like this.
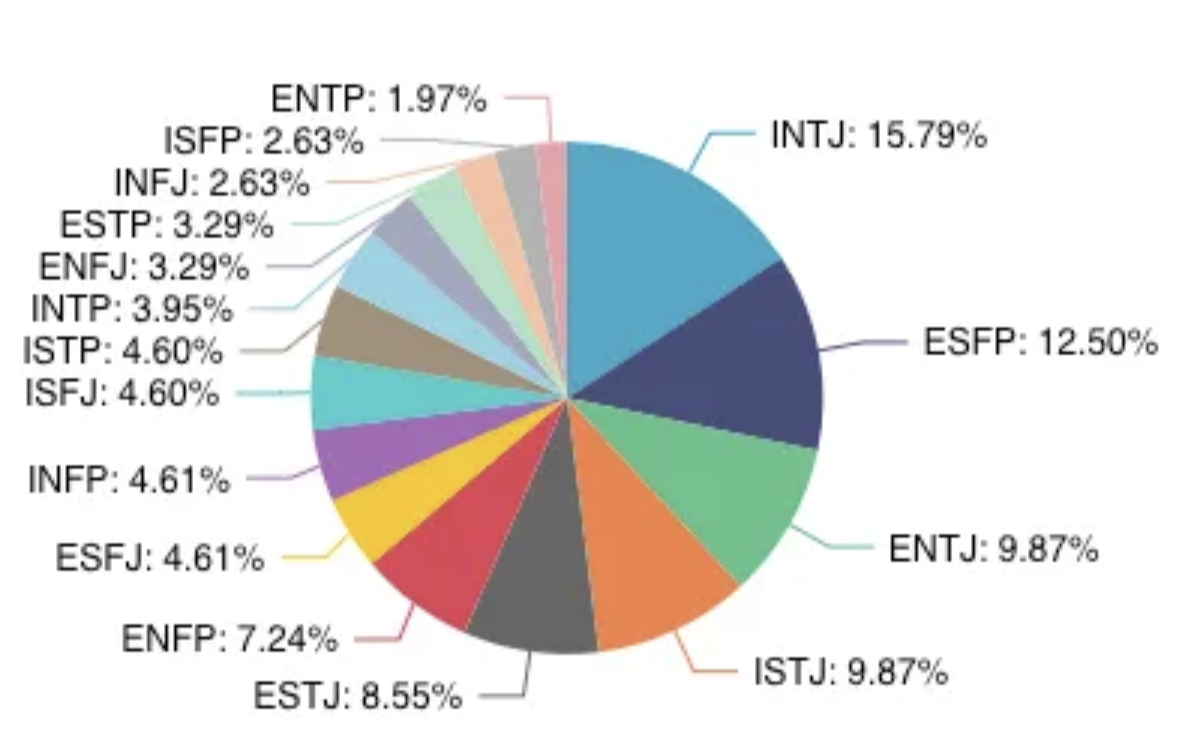
The materials of our needle.
The sessions consisted of questionnaires with different types of questions made by our typology experts. These included:
- Multiple choice - with and without an “Unclear” option.
- Sliders - similar to multiple choice, but where people could express how much they agree.
- Open text questions - open text questions for text analysis.
The options to the multiple choice and slider questions were made with some typology meaning behind each option, similarly with the questions on other open typology questionnaires. However, the main plan is to study the answering statistics rather than relying on the typology meaning of the answers. There are always many possible interpretations to each option and each individual life experience might make people choose differently even when they are alike.
Process.
Groups of questions were distributed in batches via a user testing platform. We collect both the responses and videos of the people filling out the questionnaire while expressing their thoughts out loud. Afterward, our typology experts reviewed the videos to assess users’ personality types and assign confidence levels to their assessment. We also provide the experts with the option of stating some partial typing information such as specific dimensions or strong cognitive functions observed.
The end result is a set of answers to questions where we also have the type of the people that filled in those answers. This information is complemented with the expert confidence values for each user, so that we can filter out sessions where our experts are not so sure of the user’s type.
Show: Showing is caring.
This collected data gave us all sorts of insights. We will now go over some of our learnings. First off, we will start by describing the metrics we use to measure performance, and then we will present the values we got for those metrics.
Evaluation metrics.
The typing problem is, in essence, a classification one. One of the main metrics we have to calculate the performance of such a system is standard accuracy. With accuracy you get the simple ratio of correct type guesses divided by all type guesses.
With typical accuracy, simply identifying the most common types can yield a high score. An extreme example would be if most of the group are ESTJs. If you guessed everyone’s an ESTJ, you’d still end up with good-looking results.
We strive to get to know everyone and as such we needed a metric that also gives voice to minorities and punishes us from relying only on common types. We tackle this with the F1 score. F1 gives us a balanced score per type, that we equally average over all types, i.e. macro-averaged F1. Every time we mention F1 for a typing system, we mean this macro-averaged F1.
Knowing our starting point - evaluation on 16p and CK.
Using this framework, we evaluated the performance of the 16Personalities and Crystal Knows online typology questionnaires.
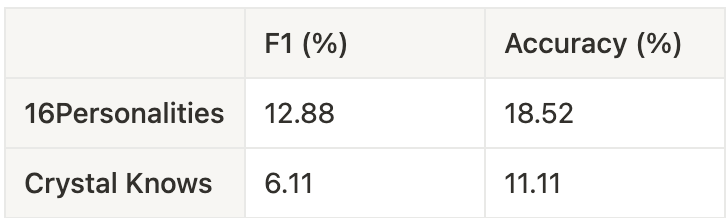
Go: Our first bet.
As mentioned, rather than relying heavily on typological concepts, we conducted a thorough analysis of the answers provided by individuals of each type. People of different cultures answer differently, people with different life experiences answer differently and the situations that we remember when answering to a typing questionnaire vary from time to time. Using the data collected, we explored every possible statistic to build our AI model. This would not be possible without all the data collected with labels based on human typology-expert reviews.
Data handling and safeguards.
To ensure we reduced the bias as much as possible, we made careful division of the available data. Every session by a user that filled in both 16Personalities and Crystal Knows questionnaires was included in an evaluation dataset. We only rely on this dataset for evaluation purposes to provide a comparison as fair as we can.
The remaining data formed our working dataset. It was used and split in many ways depending on each model we tried. For example, imagine you are testing a statistical model using a subset of questions. The decisions regarding the choice of questions to use and any tuning of the statistical model are done using this working dataset, leaving the evaluation dataset only for evaluation purposes.
Performance.
While the typing performance of our GO! model isn’t yet at the level we aim for, it shows a substantial improvement compared to current open solutions.
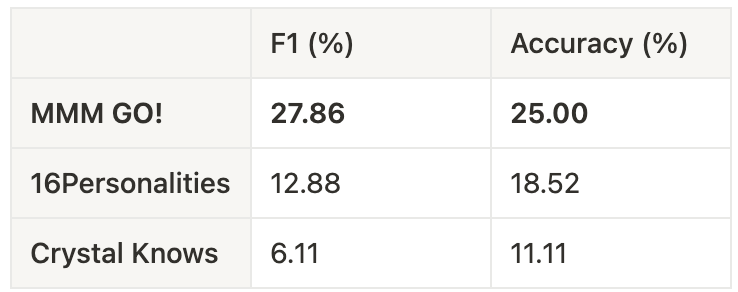
Our first try will not be our last. To go and build your dreams, you need to go! and start somewhere. This is why we called our first typing model GO!. Our data is still being built, and building a curated dataset with human-typed people takes time. In this snapshot, the quantity we gathered left us confident enough to build a closed question questionnaire that improves on existing online typing questionnaires.
This is our first step and we still have many more things to try out. So stay in tune for more updates where we march towards the 90%+ mark in performance, with more and more formats other than simple multiple-choice Q&A!
Flow: The future and next steps.
GO! marks the beginning of our story and in the next months we will flow with life every day we go to work to put another brick on the world’s best non-human MBTI typer. We already started collecting open text responses to different questions, and tested various chatbots to engage with you and learn about you. Expect much more from us—and, of course, from yourself.